I. 项目初衷 Purpose of This Project
项目因日常生活中留学生群体对英国水质的批评所启发
在英中国留学生普遍认为英国水质较差,英国的水质容易引发掉发等问题,因此通过对英国水质数据进行数据分析,并与中国的水质数据的比对,客观明确地反映两国水质的差异。
II. 数据来源 Data Source
项目的数据来源于英国环境、食品和农村事务部(Department for Environment Food & Rural Affairs)官网的统计数据,数据的时间范围是2000年-2023年(注:在分析项目开始时此数据最近一次的更新在2023年的3月18号。)数据的采样点包括英国各地的海岸,河口,湖泊,池塘,水渠和地下水。
———————2023/4/13———————
乍一看官网的数据介绍,数据是有残缺的,但不知道具体是怎么样的,所以让我们下载一份看看区别在哪。

在下载界面可以看到数据的整理特别的规范,这里不得不夸赞一下英国政府信息公开服务的质量。

由于我们想要研究的是整体的水质情况,这里我们只关注所有地区的数据集,或许在完成这个大项目后可以再研究一下我所在的地方的水质情况在英国大概是什么样的。
同时我们可以看到,数据集被分为了Monitoring和Compliance两类,通过搜索后发现,两者之间的区别主要在于它们的目的和采集方式。Monitoring data是通过定期采集数据,监测水体质量变化趋势,Compliance data则是根据相关规定等进行采集,旨在评估水质是否符合特定的法规、标准或规定。因此我们选择Monitoring data进行分析,因为它更适合于研究水质的整体状况。(又学到了一点专业术语的知识!)
接下来我们用Jupyter Notebook打开原始数据,由于数据内容较多,使用了pd.set_option()对版面进行了调整。
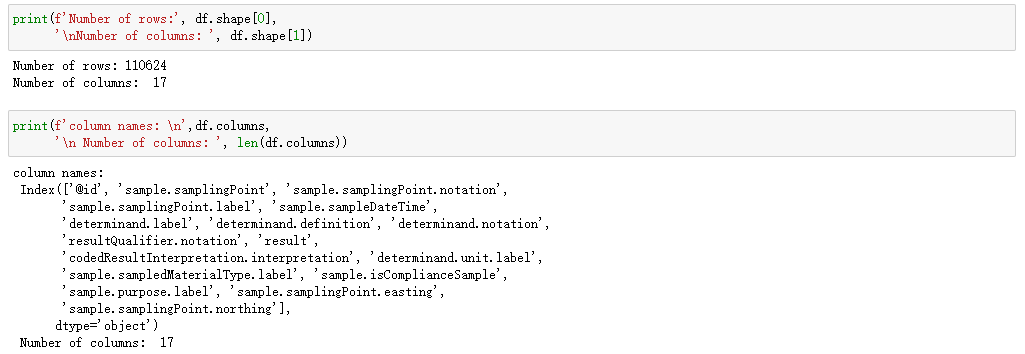
可以看到2023的monitoring文件中有110624行,17列的数据,进一步观察数据:
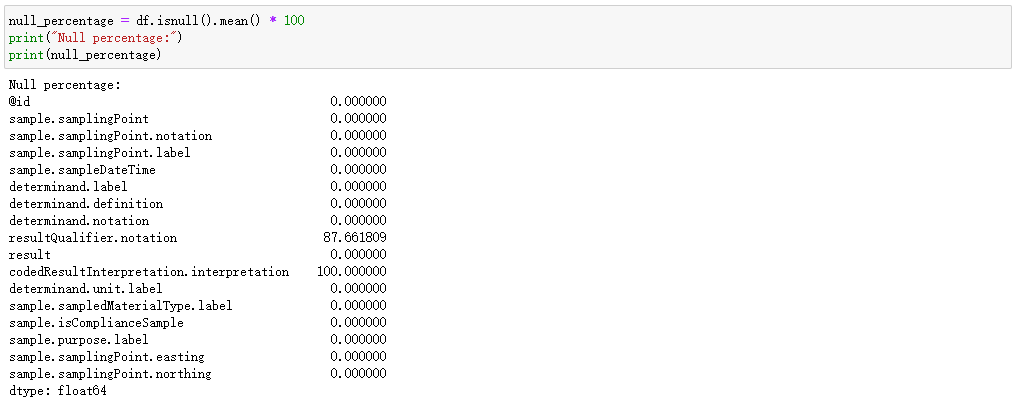
| 列名 | 中文翻译 | 作用和意义 | 空值占比(%) |
|---|---|---|---|
| ‘@id’ | 样品唯一标识符 | 用于唯一标识每个样品 | 0 |
| ‘sample.samplingPoint’ | 采样点标识符 | 记录样品采集的位置信息 | 0 |
| ‘sample.samplingPoint.notation’ | 采样点的符号化表示法 | 描述采样点的符号化标记信息 | 0 |
| ‘sample.samplingPoint.label’ | 采样点标签 | 描述采样点的自然语言标签 | 0 |
| ‘sample.sampleDateTime’ | 样品采集时间 | 记录样品采集的时间 | 0 |
| ‘determinand.label’ | 检测物质标签 | 描述被检测物质的名称 | 0 |
| ‘determinand.definition’ | 检测物质定义 | 描述被检测物质的定义、特性 | 0 |
| ‘determinand.notation’ | 检测物质的符号化表示法 | 描述被检测物质的符号化标记信息 | 0 |
| ‘resultQualifier.notation’ | 结果质量限制的符号化表示法 | 描述结果质量限制的符号化标记信息 | 87.66 |
| ‘result’ | 检测结果 | 描述被检测物质在样品中的浓度值 | 0 |
| ‘codedResultInterpretation.interpretation’ | 被编码的结果的解释 | 通过编码的形式描述结果的解释信息 | 100 |
| ‘determinand.unit.label’ | 检测物质浓度单位标签 | 描述检测物质浓度值的单位 | 0 |
| ‘sample.sampledMaterialType.label’ | 样品采集的水体类型 | 描述样品采集的水体类型 | 0 |
| ‘sample.isComplianceSample’ | 是否是符合检测标准的样本 | 描述该样品是否符合特定的水质标准或法规的要求的检测样本 | 0 |
| ‘sample.purpose.label’ | 样品采集目的 | 描述样品采集的目的 | 0 |
| ‘sample.samplingPoint.easting’ | 采样点东经 | 描述采样点的地理坐标系统中的东经 | 0 |
| ‘sample.samplingPoint.northing’ | 采样点北纬 | 描述采样点的地理坐标系统中的北纬 | 0 |
| Field | Meaning | Type | Occurs | Views |
|---|---|---|---|---|
codedResultInterpretation | Gives the interpetation of a coded result value. | def-det:CodedResultInterpretation | optional | full, default, compact |
codedResultInterpretation.interpretation | The interpretation of a coded result | full, default, compact | ||
determinand | The determinand, i.e. the property that was measured. | def-det:Determinand | full, default, compact | |
determinand.definition | The definition of the determinand. | xsd:string | full, default | |
determinand.label | A name for the determinand. | rdf:langString | full, default, compact | |
determinand.notation | A string or other literal which uniquely identifies the determinand. | full, default | ||
determinand.unit | The units in which the determinand is measured. | full, default, compact | ||
determinand.unit.label | A name for the determinand.unit. | rdf:langString | full, default, compact | |
result | A property for conveying the numeric value of a measurement. The units of measure for interpreting the measurement result are a property of measurements determinand. Some measurements have a coded result (determinand.unit=def-units:0992) in which case an additional codedResult property is present that which references the interpretation of the coded value. | xsd:decimal | full, default, compact | |
resultQualifier | A qualifier for the result, e.g. to indicate that the stated result is a lower or upper bound for the actual value | def-sample:ResultQualifier | optional | full, default, compact |
resultQualifier.notation | A string or other literal which uniquely identifies the resultQualifier. | full, default, compact | ||
sample | The sample to which this measurement applies | def-sample:Sample | full, default, compact | |
sample.isComplianceSample | An attribute of a :Sample used to indicate whether the sample has been collected for a compliance purpose. The detailed purpose for which the sample has been collected can be determined by examing its :purpose property. | xsd:boolean | optional | full, default |
sample.purpose | A property for expressing the purpose of a water quality sample was taken. | def-sample:Purpose | optional | full, default |
sample.purpose.label | A name for the sample.purpose. | rdf:langString | full, default | |
sample.sampleDateTime | A property for expressing the date and time that a sample was collected. | xsd:dateTime | full, default, compact | |
sample.sampledMaterialType | The type of material sampled | def-sample:SampledMaterialType | optional | full, default |
sample.sampledMaterialType.label | A name for the sample.sampledMaterialType. | rdf:langString | full, default | |
sample.samplingPoint | An open-domained property for making reference to a sampling point. | def-sp:SamplingPoint | full, default, compact | |
sample.samplingPoint.area | An open-domained property for referencing an Environment Agency area | def-eaorg:Area | full | |
sample.samplingPoint.easting | The easting of the point on the British National Grid | xsd:integer | full, default | |
sample.samplingPoint.label | A name for the sample.samplingPoint. | rdf:langString | full, default | |
sample.samplingPoint.lat | The latitude of the point in WGS84 coordinates | xsd:decimal | full | |
sample.samplingPoint.long | The longitude of the point in WGS84 coordinates | xsd:decimal | full | |
sample.samplingPoint.northing | The easting of the point on the British National Grid | xsd:integer | full, default | |
sample.samplingPoint.subArea | An open-domained property for referencing an Environment Agency sub-area | def-eaorg:SubArea | optional | full |
我们再来具体查看一下数据集的内容:
'@id', 'sample.samplingPoint', 'sample.samplingPoint.notation', 'sample.samplingPoint.label'
a. 数据集的前1-4列交代了样本采样的地点信息,除第一列是唯一值以外,其他三列都有重复的值,反映出这一年的采样主要有3670个采样点

b. 数据集的第5列为样本采样的时间信息,不难看出有写区域有不同时间段的采样记录
'sample.sampleDateTime'

c. 数据集的第6-12列为核心内容,展示了样本测定的物质及参数,是对水质特性的定量描述,通过nunique可以发现,数据集一共记录了水中508种物质的含量
'determinand.label', 'determinand.definition', 'determinand.notation', 'resultQualifier.notation', 'result', 'codedResultInterpretation.interpretation', 'determinand.unit.label'
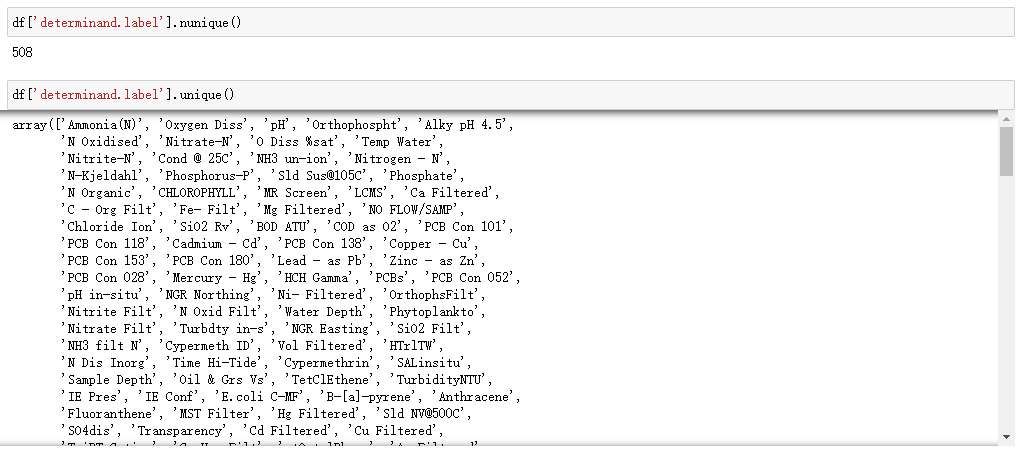
d. 数据集的第13-17列展示了样本采集地的所属分类,以及是否合规,采集目的,地理坐标
'sample.sampledMaterialType.label', 'sample.isComplianceSample', 'sample.purpose.label', 'sample.samplingPoint.easting', 'sample.samplingPoint.northing'
这其中’sample.sampledMaterialType.label’也是对项目非常有用的信息:

| 水样类型 | 描述 |
|---|---|
| RIVER / RUNNING SURFACE WATER | 河流/流动地表水 |
| GROUNDWATER | 地下水 |
| ESTUARINE WATER | 河口水 |
| GROUNDWATER – PURGED/PUMPED/REFILLED | 地下水-排放/泵送/补给 |
| POND / LAKE / RESERVOIR WATER | 池塘/湖泊/水库水 |
| SEA WATER | 海水 |
| CANAL WATER | 运河水 |
| GROUNDWATER – STATIC/UNPURGED | 地下水-静态/未排放 |
| ANY SOLID/SEDIMENT – UNSPECIFIED | 任何固体/沉积物-未指定 |
| ANY TRADE EFFLUENT | 任何商业废水 |
| ANY SEWAGE | 任何污水 |
| MINEWATER | 矿井水 |
| SURFACE DRAINAGE | 地表排水 |
| FINAL SEWAGE EFFLUENT | 终端污水 |
| STORM SEWER OVERFLOW DISCHARGE | 暴雨下水道溢流排放 |
| PRECIPITATION | 降水 |
| CALIBRATION WATER | 校准水 |
| ESTUARINE WATER AT HIGH TIDE | 高潮时的河口水 |
| ANY WATER | 任何水样 |
| ANY LEACHATE | 任何浸出液 |
| MINEWATER (FLOWING/PUMPED) | 矿井水(流动/抽取),指从矿井中流出或通过抽水泵抽取的水样。 |
分析到这里,有几点想法:
- ‘codedResultInterpretation.interpretation’ 这一列是需要被剔除的,因为该列所有值都为空值;
- determinand的选择。在水质监测中,选择合适的determinand是非常重要的,因为不同的determinand可以反映出水质的不同方面,如饮用水、水生态、工业废水等不同场景需要测量不同的determinand。而且,不同的determinand的测量方法、标准和限值也各不相同,需要根据具体情况进行选择和使用。
- 我对这个项目的预估还是太浅薄了。原来水质的对比也有很多种,我准备分析的是生活用水,即饮用水,和日常用水,因此需要选择RIVER / RUNNING SURFACE WATER,GROUNDWATER,GROUNDWATER – PURGED/PUMPED/REFILLED和POND / LAKE / RESERVOIR WATER四种水体的样本来进行分析
- “整体”的概念要如何定义?地区与地区之间已经有差异,且差异还进一步体现在于各种水体的不同,而中国和英国都是幅员辽阔的国家,要怎么确定好对比的主体?
- 虽然还没有开始收集中国的水体数据,但我感觉数据颗粒度应该不比英国,且数据的收集过程中,数据的真实性,数据采集的标准等都将成为误差的来源。
———————2023/4/14———————
继续这个项目的研究。在查找中国水质数据的过程中想到还有一个区别是四季的区别。但是目前来看似乎没有办法收集到像英国官网提供的那么全的数据,我试着搜了一下印度的,发现也整理的很齐全,中国的统计数据可信度暂且放一边,但信息公开的服务是真的很落后。不由得联想起之前看新闻说的28:1的官民配比,啧啧称奇。
由于无法查询到中国水质的历史数据,项目的目标需要做一些修改。
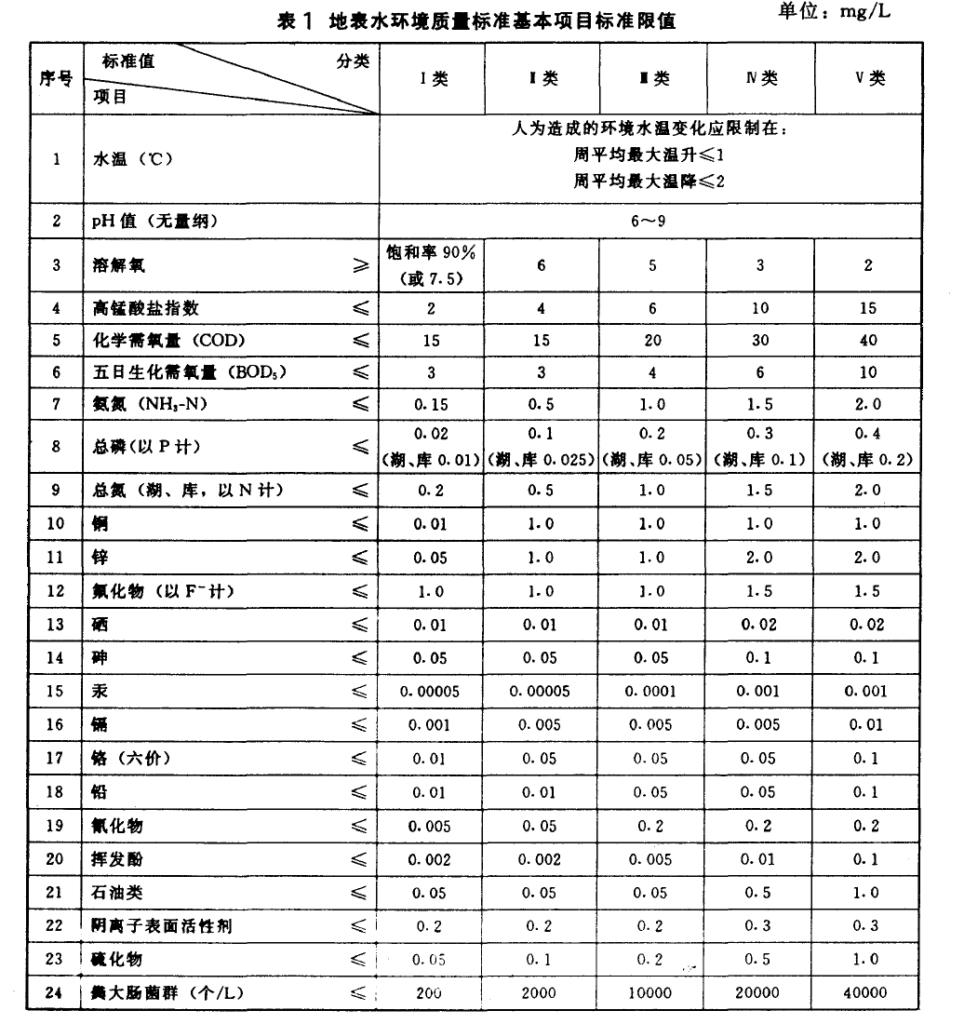
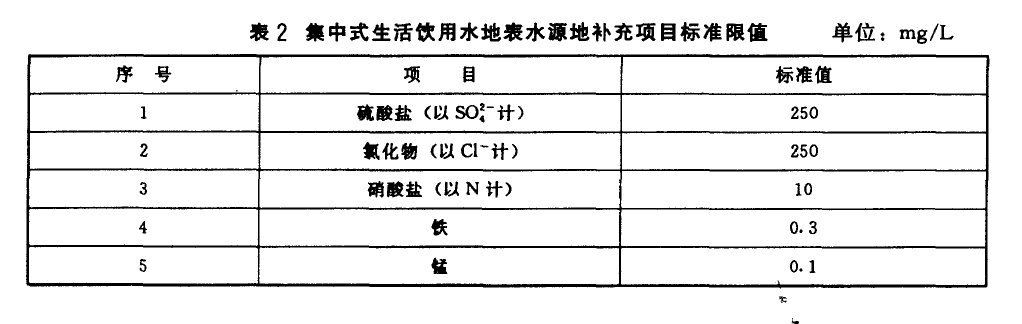
当前项目的目标为,根据中华人民共和国《地表水环境质量标准GB3838-2002》 中对I,II,III,IV,V五类地表水划分标准,对英国各地水质数据进行分类,并与中国的水质实时监测数据进行对比,从而判断英国水质情况。
中国数据:
先用python进行数据处理,将需要用到的物质提取出来,同时要将湖泊水,河流水和地下水提取出来,之后就可以进行对比了。
———————2023/04/16-2023/04/17———————
P.S. 这两天没怎么写文字,因为都在研究代码和数据。顺便今天是17号,收到了E·ON Next Data Analyst的拒信,好吧有点失落,看了一下Steve Jobs 的斯坦福演讲回了回血,人生无法往前串点,只能回头看时把发生过的事连接起来。所以尽量做好自己当下的事情吧!
———————2023/04/17-2023/04/28———————
项目的进展落后了很多,过程中,电脑硬盘坏了,其他生活的电器也莫名其妙地坏了,加上最近人有些emo,所以停滞了11天。现在继续这个项目。
我发现这个项目有点运行不下去,原因是,就算英国的统计数据够多,但是我发现并不是所有的采样点都满足有19个采样数据分类,因此数据处理最后得到的应该是一张有很多na值的表,所以我的评价标准也需要响应做出改变,只能退而求其次,通过比对各种已有的数据中的最低值来进行分类,做一个大概的评估。
然后过滤出核心的一些指标,像是ph值,各个分类做visualization。
附录:
关于水质硬度的介绍:

中国的国家水质划分标准: